
DeepSeek—a rapidly emerging AI startup based in China—has turned heads worldwide by delivering DeepSeek Efficiency in its AI solutions. Best known for its R1 model, DeepSeek has managed to compete with industry behemoths like OpenAI and Meta while operating on a much leaner budget. This unlikely success story challenges the long-held belief that only massive investment leads to AI supremacy, paving the way for more cost-effective and innovative paths in AI research.
Hardware and Training Efficiency
Cost-Effective Training
A key aspect of DeepSeek Efficiency is the company’s claim that it developed its latest AI models for around $5.6 million—pocket change compared to the billions poured in by tech giants such as OpenAI and Google. While some analysts question the accuracy of these figures, there is a general consensus that DeepSeek’s costs are significantly lower than its competitors’. This affordability underpins the startup’s reputation for resourceful AI development.
GPU Usage
DeepSeek’s models rely on existing technology and open-source software, showcasing DeepSeek Efficiency through minimal reliance on cutting-edge hardware. Although the company primarily employs Nvidia H800 GPUs, rumors suggest it also stockpiled H100 chips before export bans tightened. Regardless, DeepSeek’s ability to train high-performing models with relatively modest chips highlights a potential gap in U.S. export controls. The startup maintains it uses special versions of Nvidia GPUs intended for the Chinese market.
Efficient Training Techniques
DeepSeek’s training methods reinforce DeepSeek Efficiency by combining advanced techniques that cut down on computational overhead:
- Mixture of Experts (MoE): Coordinates multiple smaller AI models to tackle user queries, reducing the need for massive datasets and the latest GPUs.
- Reinforcement Learning (RL): The R1-Zero model evolves on its own via pure RL, while the R1 model blends RL with supervised fine-tuning, refining both performance and readability.
- Distillation: By transferring knowledge from the large R1 model into smaller ones (such as Qwen and Llama), DeepSeek preserves core functionality while lowering resource requirements.
DeepSeek Model Results
R1 Model Performance
DeepSeek’s R1 model epitomizes DeepSeek Efficiency in action. Rivaling OpenAI’s o1 in reasoning tasks, the open-source R1 gives developers worldwide the opportunity to modify and integrate an advanced AI at comparatively low costs.
Benchmark Comparisons
- Mathematics: DeepSeek-R1 outperforms OpenAI’s o1-1217 on both MATH-500 (97.3% vs 96.4%) and AIME 2024 (79.8% vs 79.2%).
- Coding: In software engineering tasks like SWE-bench Verified, DeepSeek-R1 (49.2%) edges out o1-1217 (48.9%). OpenAI’s model retains a slight lead on Codeforces, suggesting a nuanced advantage.
- General Knowledge: OpenAI’s o1-1217 fares better in broad problem-solving (GPQA Diamond at 75.7% vs DeepSeek-R1’s 71.5%, and MMLU at 91.8% vs 90.8%).
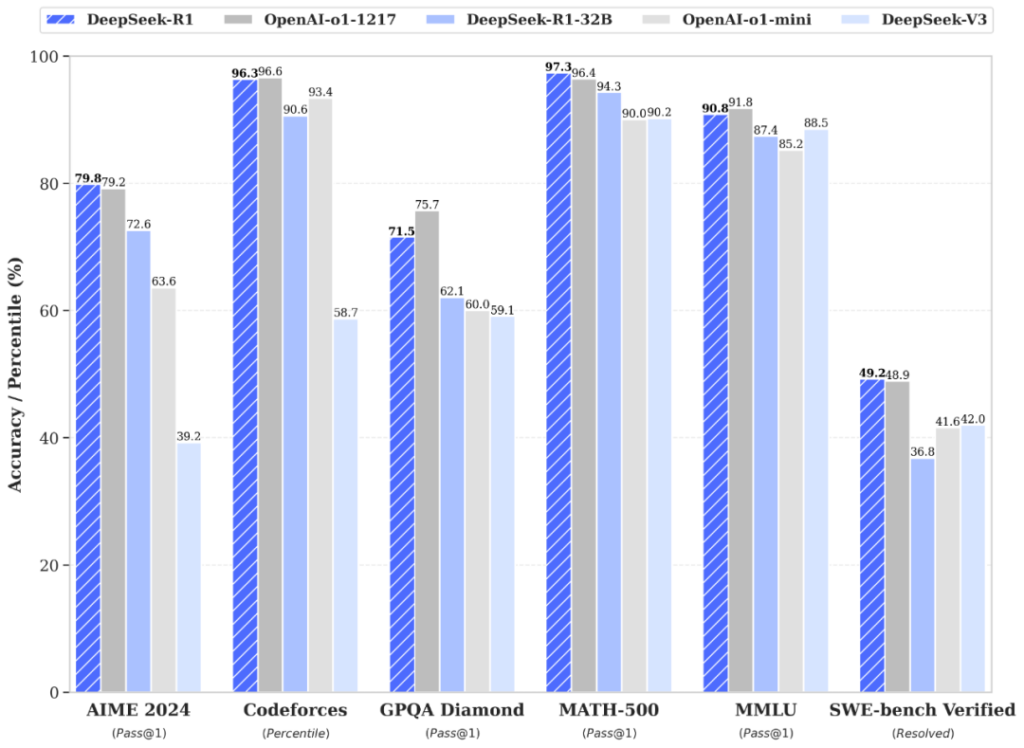
Overall, DeepSeek Efficiency leads to strong performance in math and software benchmarks, while OpenAI’s model excels in general knowledge tasks.
Cost and Accessibility
DeepSeek offers its chat platform free (with a 50-message daily cap), complementing its affordable API that charges $0.55 per million tokens for input and $2.19 for output. When contrasted with OpenAI’s $15 (input) and $60 (output) per million tokens, this price differential underscores DeepSeek Efficiency as a game-changer for developers on tight budgets.
Distilled Models
DeepSeek further showcases DeepSeek Efficiency through distillation, creating variants like Llama 3 70B, which often surpass smaller counterparts (e.g., o1 mini) in performance. This highlights how well DeepSeek’s streamlined approach scales across diverse usage scenarios.
Comparison with Competitors
OpenAI
Although OpenAI’s o1 generally outperforms DeepSeek-R1 in coding and factual reasoning, DeepSeek Efficiency makes R1 highly competitive in math and specialized tasks, particularly given its significantly lower operating costs.
Meta
DeepSeek’s R1 model draws on open-source breakthroughs by Meta—namely, Llama—and seems to refine these concepts further. Observers note that DeepSeek Efficiency allows the startup to rival and, in some cases, surpass Meta’s offerings.
Other Chinese AI Companies
Among local competitors like ByteDance and 01.ai, DeepSeek’s R1 model has proven formidable in benchmarks. Its emphasis on open-source collaboration and DeepSeek Efficiency helps it stand out in a crowded marketplace.
Market Impact
Stock Market Disruption
DeepSeek’s surge in visibility led to a sharp sell-off in tech shares, particularly Nvidia, which experienced one of the biggest single-day drops in market value—nearly $600 billion. This turmoil highlights the market’s realization that DeepSeek Efficiency challenges the high-capital, high-infrastructure AI model once seen as the industry’s gold standard.
Challenging US Dominance
DeepSeek’s ascent questions the U.S.’s traditional hold on AI innovation, reinforcing the possibility that breakthroughs can emerge more cost-effectively elsewhere. It also raises concerns over the actual effectiveness of U.S. export controls, as DeepSeek Efficiency leverages available hardware to achieve high-level performance.
New Era of AI
By putting innovation, adaptability, and DeepSeek Efficiency at the forefront, this Chinese startup exemplifies how smaller teams can disrupt well-established giants in AI. It signals a future where swift, strategic development may overshadow heavy investments and massive data center footprints.
Limitations
Censorship
DeepSeek’s known censorship of sensitive topics (such as Tiananmen Square) may hinder its global adoption and acceptance in academic or open-knowledge circles.
Uncertainty About Costs
Skeptics question whether DeepSeek’s $5.6 million figure fully accounts for all developmental overhead, including research, algorithmic innovation, and data acquisition. Even so, any upward revision would still likely be substantially lower than the sums spent by leading AI firms—a testament to DeepSeek Efficiency in practice.
By proving it can deliver sophisticated AI capabilities on a tight budget, DeepSeek symbolizes a pivotal shift in the AI world—one defined by DeepSeek Efficiency over deep pockets. Its R1 model and related techniques validate that strategic resource allocation and open-source collaboration can indeed challenge the status quo of billion-dollar budgets. While questions remain about censorship and overall cost transparency, DeepSeek has indisputably reshaped expectations around what’s possible in AI development, paving the way for a new wave of lean, high-performance innovation.







